 深圳南山seo
深圳南山seo
Python学习笔记-爬虫(1)通过案例梳理简单爬虫的基础知识点
浏览次数:54 分类:SEO基础
写作背景:作为一名金融从业者,在个人的业务投资上,经常会需要通过数据分析,加上金融逻辑的推演决定自己的投资策略。提到数据分析,就必然会提到数据采集。作为个人投资者,数据信息最多的就是来自互联网。如何高效获取自己需要的数据并加以分析,就是在下开始学习爬虫的原因。通过记录学习情况,梳理自己的知识框架,同时也能分享给大家,找到一起努力奋斗的小伙伴。
个人背景:理工科类大学毕业,从事银行、保险等金融相关工作近10年。
编程能力:大学期间学过C语言和SQL语言,但是10年来几乎很少应用,忘得差不多。
学习Python的原因:网上关于Python的爬虫案例较多,据说Python语言相比C和JAVA更近自然语言。
学习时长:工作之后的业余时间,累计近一个月。
学习成果:掌握简单的爬虫技术。
系统环境:windows 10
IDE:Pycharm
Python版本:Python2.7 (Ananconda)
知识点:1、涉及到的库urllib,urllib2,re,beautifulsoup,lxml,gzip,StringIO,csv,mysql
2、掌握用urllib,urllib2获取网页
1)最简单的获取方式urllib2.urlopen()
2)加入报头headers
3)加入代理proxy
4)加入cookies
5)定制自己的opener
6)网页乱码的处理:chardet、decode()、gzip、StringIO库
3、通过网页解析,获得需要的数据
1)学会用正则表达式解析
2)学会用BeautifulSoup解析网页
3)学会用lxml xpath解析网页
4、数据的读写
1)txt文件的读写
2)CSV文件的读写
3)MySQL的读写
本文适用人群:零基础学爬虫、小白学爬虫、简单爬虫的学习框架
其他:1)本文通过爬虫案例学习以上学习以上知识点。并尽可能对每一段代码做注解,
注解开头为#。
2)本文不会涉及到class类和函数的概念,便于初学者学习基本知识。
3)本文仅作为知识学习的笔记与分享,请勿在未经作者的同意下商用seo爬虫基础知识,更希望每一个编程爱好者以阳光的心态学习,不要用于违法乱纪。
参考网站:1)廖雪峰的Python 2.7教程:学习所有Python的最基础语法,当词典用。
2)简明 Python 教程,当词典用
3)崔庆才的个人博客,Python爬虫学习系列教程 | 静觅,相当多的实例教程,唯一 缺点就是很多文章是半年前到1年前写的,很多网页都纷纷改版,直接运行里 面的代码无法爬取,但是可以作为爬虫思路的指引。
爬取对象:上海房产网_上海二手房_上海新房_上海租房-上海链家网
感谢链家网,提供了很好的学习土壤。
我是分割线————————————————————————————————————
正文与代码:
<code class="language-python"># encoding: utf-8
#该行注释是为了解决python中文的乱码问题,所有中文以utf-8格式解析,也可以写成 # -*- coding: utf-8 -*-
1、添加需要用到的库urllib,urllib2,re,beautifulsoup,lxml,csv,mysql,gzip,StringIO
import urllib #网页解析库
import urllib2 #网页解析库
import re # 正则表达式的库
import cookielib #cookie的库
from bs4 import BeautifulSoup # BeautifulSoup的库
import lxml.html # lxml xpath的库
from lxml import etree # lxml xpath的库
import csv #csv的库
from mysql import connector # 连接MySQL的库库的安装命令,cmd下执行:pip install urllib
pip install urllib==1.0.0 #制定版本的库安装
pip install –upgrade urllib #库的升级
其他pip命令可以参考:pip安装使用详解 – 爱开源

2、掌握用urllib,urllib2获取网页
1)最简单的形式:
url = 'http://sh.lianjia.com/ershoufang/d1'
response = urllib2.urlopen(url)
content = response.read()
print content
输出结果:
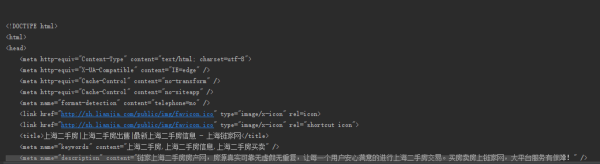
说明爬取成功,看来链家非常的友好,并没有设立针对urlopen显性的反爬虫机制。
怎么判断爬取是否成功
print content.getcode()如果返回值是200则爬取成功,如果是301、302则是重定位,如果是404则是表示页面不存在
详细可以参考 301、404、200、304等HTTP状态 – Lynn.Zhou的专栏 – 博客频道 – CSDN.NET
2)加入报头headers,如果遇到有显性反爬虫机制的情况,返回一般就不是200了,这个时候怎么办?就给爬虫带个帽子,假装自己不是爬虫。
headers = {
'User - Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}报头一般用浏览器按F12,查看Network选项卡里都能看到,实在不行,你可以把整个Request Headers里的内容,以字典的方式扔进去。
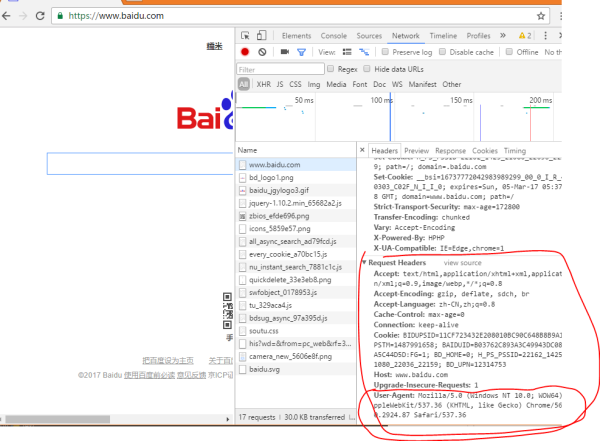
3)尝试加入代理IP机制,现在越来越多的网站 没有显性的反爬虫模式,而是采用隐性的反爬虫机制,比如你开始爬取第一页的时候没问题,但是爬着爬着就把你BAN了,而一般BAN的是你的IP地址,所以在做大量数据爬取的时候建议加入IP代理机制。
代理IP地址怎么获取,请自行百度或者谷歌。
proxy_handler = urllib2.ProxyHandler({"http": '101.231.67.202:808'})
opener = urllib2.build_opener(proxy_handler,urllib2.HTTPHandler)
4)加入cookies
cookie = cookielib.LWPCookieJar()
cookie_handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(cookie_handler,urllib2.HTTPHandler)5)定制自己的opener
#同时加入proxy和cookie
opener = urllib2.build_opener(proxy_handler,cookie_handler,urllib2.HTTPHandler)6)网页乱码的处理:chardet、decode()、gzip、StringIO 乱码表现一:chardet、decode()
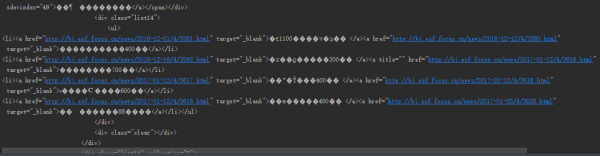

有时解析网页会发现大量的奇怪符号,嗯,这就是乱码。乱码的一般都是中文。
访问的网站是搜狐,同样调取查看器。
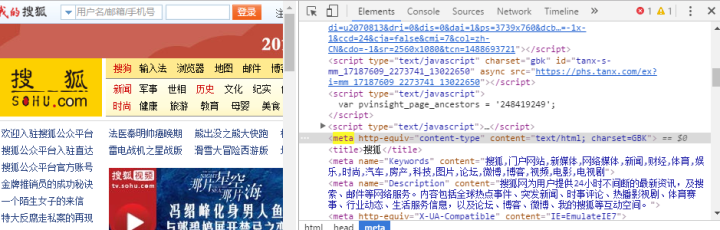
在里有以下内容:
说明网站的中文是用GBK的。
print content.read().decode('gbk')
decode的其他形式:decode('utf-8','ignore') #忽略不能解码的内容,确保命令正常运行
用chardet的库来解析网络的代码
import chardet
url = 'http://www.sohu.com'
response = urllib2.urlopen(url)
content = response.read()
charset_info = chardet.detect(content)
print charset_info
乱码表现二:调用gzip、StringIO库

所有的内容都乱码了。。。。
明明是gb2312,用decode('gbk','ignore')居然不能解码。。。
乱码的网页报头
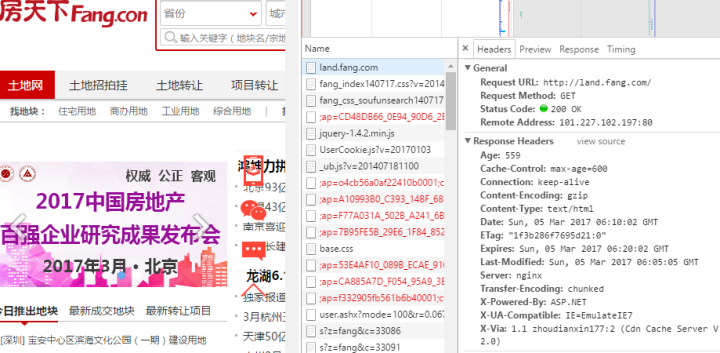
普通网页的报头

关键在于RESPONSE里是否有 Vary:Accept-Encoding。如果没有申明,网页要自行解压。
gzip和StringIO派上用处了:
import gzip
import StringIO
url = 'http://land.fang.com'
response = urllib2.urlopen(url)
content = response.read()
content = StringIO.StringIO(content)
gzipper = gzip.GzipFile(fileobj=content)
content = gzipper.read().decode('gbk')
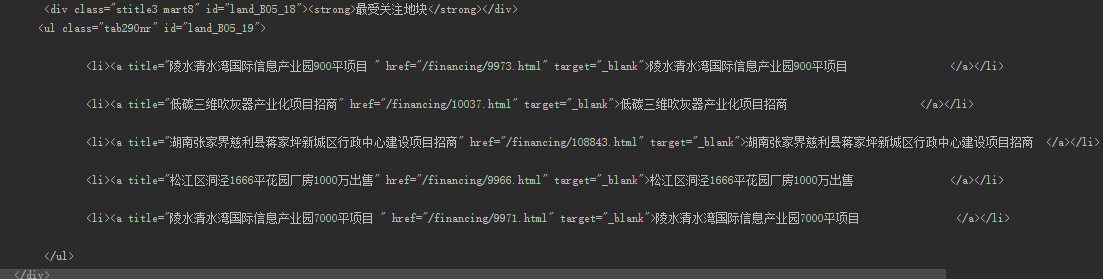
3、通过网页解析,获得需要的数据
还是以上海二手房|上海二手房出售|最新上海二手房信息 – 上海链家网为案例
获取所有行政区的链接和名字
1)学会用正则表达式解析
pattern_district = re.compile('(.*?)', re.S)
districts = re.findall(pattern_district, content)
for district in districts:
print district
熟练掌握.*?和(.*?)的贪婪匹配技巧seo爬虫基础知识,一般都能轻松获取
但是如果要获取行政区的链接就很痛苦了,因为正则表达式只能找规律,周围匹配的字段越特殊,那么越容易找到。
pattern_district = re.compile('(.*?)', re.S)
districts = re.findall(pattern_district, content)
for district in districts:
print district 这样写的结果,会匹配到很多不想管的内容

打包一起找再处理
pattern_district = re.compile('<a href="/ershoufang/".*?.*?(.*?)',re.S)
districts = re.findall(pattern_district, content)
districts =districts[0]
print districts
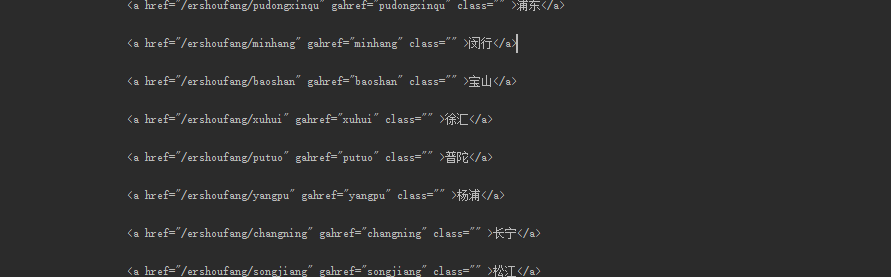
再一次正则匹配:
pattern = re.compile('(.*?)',re.S)
item = re.findall(pattern,districts)
for i in item:
print i[0], i[1]
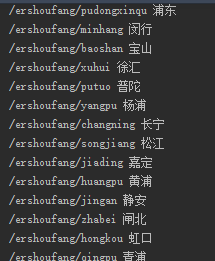
是不是有种抠图的快感,哈哈。
2)学会用BeautifulSoup解析网页
from bs4 import BeautifulSoup
print type(content)
soup = BeautifulSoup(content,'lxml')
print type(soup.prettify())
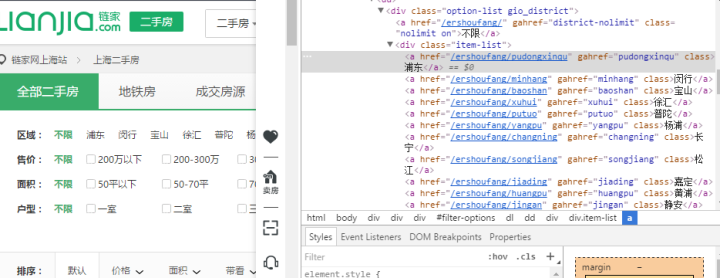
#搜索行政区域
items = soup.find('div',class_="option-list gio_district").find_all('a',class_="")
# print items
for item in items:
district = item.get_text()
district_url = item.get('href')
print district,district_ur
find()找到第一个匹配的内容就返回,find_all找到所有匹配的内容,get_text()获取标签内的文本内容,get('href')获取标签内的属性值。
用BeautifulSoup的感觉是不是逻辑很清晰?类似人类语言?
3)学会用lxml xpath解析网页
from lxml import etree
tree = lxml.html.fromstring(content)
html = lxml.html.tostring(tree,pretty_print=True)或者
from lxml import etree
tree = etree.HTML(content)
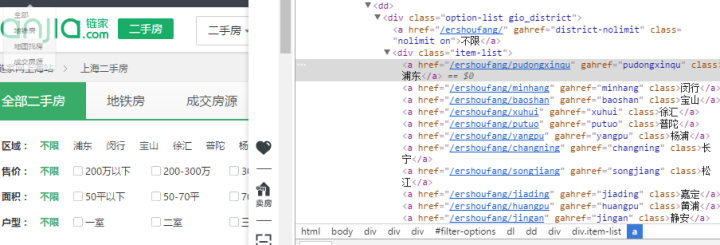
html = etree.tostring(html)#获取行政区列表
results = tree.xpath('//div[@class="option-list gio_district"]/div[@class="item-list"]/a')
for district in results:
print district.text#获取行政区链接
district_url = tree.xpath('//div[@class="option-list gio_district"]/div[@class="item-list"]/a/@href')
for district_url in district_url:
print 'http://sh.lianjia.com/ershoufang'+district_url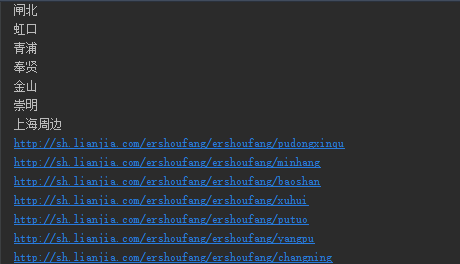
lxml xpath的逻辑也很清晰。
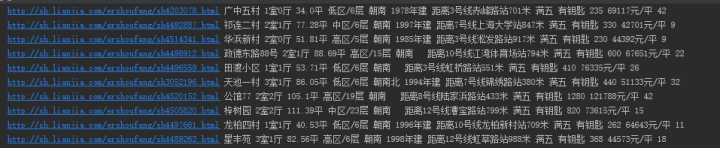
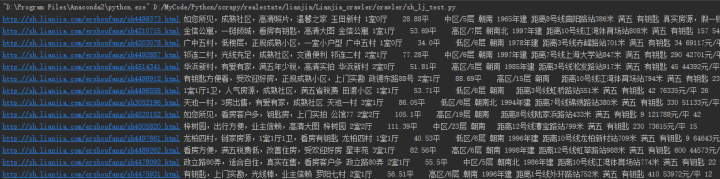
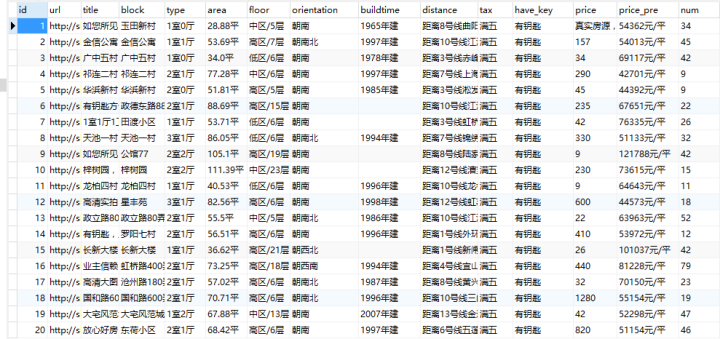
获取每一个房子的内容信息:

都在的标签下
难点:需要获取的内容不在标准的标签内。
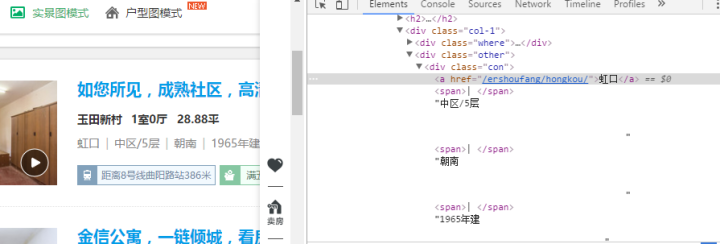
1)学会用正则表达式解析
# 对象是content,用正则表达式去匹配房子信息:下层链接,小区,户型,面积,楼层、朝向、建造时间,描述1,描述2,描述3,总价,单价,查看人数
# 无法匹配到| 下 楼层、朝向、建造时间的内容
pattern = re.compile('.*?.*?<a name.*? href="(.*?)" title'
'.*?.*?(.*?)'
' .*?(.*?) '
'.*?(.*?) '
# '.*?.*?<a href=.*?| (.*?).*?'
'.*?.*?<a href=.*?(.*?).*?'
# '.*?.*?<a href=.*?|(*?)'
'.*?(.*?)'
'.*?(.*?)'
'.*?(.*?)'
'.*?(.*?)'
'.*?(.*?)'
'.*?(.*?)'
, re.S)
items = re.findall(pattern, content)
# print items
new_item = []
for item in items:
# print item[5],item[6],item[7],item[8],item[9],item[10]
# print item[0],item[1],item[2],item[3],item[4]
#g给子项链接补完
new_item0 = "http://sh.lianjia.com" + item[0]
#难点ch,楼层、朝向和建造时间需要再处理提取
new_item4 = item[4].strip()
new_item4 = new_item4.replace('n','')
# new_item4 = new_item4.replace(' ','')
new_item4 = new_item4.replace('t', '')
new_item4 = new_item4.split('| ')
#建造时间不是每一项都有,对于没有的要补完
if len(new_item4)<3:
new_item4.append(' ')
# print new_item4
#创建新的字段
new_item.append([new_item0,item[1],item[2],item[3],new_item4[0],new_item4[1],new_item4[2],item[5],item[6],item[7],item[8],item[9],item[10]])
for i in new_item:
print i[0],i[1],i[2],i[3],i[4],i[5],i[6],i[7],i[8],i[9],i[10],i[11],i[12]

2)学会用BeautifulSoup解析网页
soup = BeautifulSoup(content,'lxml')
# print soup.prettify()
#对象为soup
# 获取房子信息:下层链接,标题,小区,户型,面积,楼层、朝向、建造时间,距离,满五,钥匙,总价,单价,查看人数
items2 = soup.find('ul',id="house-lst").find_all('li')
# print items2
datas = []
for item in items2:
#子链接
url = item.find('h2').a.get('href')
url = "http://sh.lianjia.com"+url
#标题
title = item.find('h2').a.get_text()
#小区
block = item.find('div',class_='col-1').a.get_text()
#户型
type = item.find('div',class_='where').find_all('span')[1].get_text()
#面积
area = item.find('div',class_='where').find_all('span')[2].get_text()
#楼层、朝向、建造时间比较难获取
text = item.find('div',class_='con').get_text()
text = text.replace("n","").replace("t","").replace(" ","").split("|")
#楼层
floor =text[1]
#朝向
orientation = text[2]
#建造时间
if len(text) ==4:
buildtime = text[3]
else:
buildtime = " "
#距离
if item.find('span',class_="fang-subway-ex"):
distance = item.find('span',class_="fang-subway-ex").span.get_text()
else:
distance = " "
#满五免税
tax = item.find('span',class_="taxfree-ex").span.get_text()
#钥匙
key = item.find('span',class_='haskey-ex').span.get_text()
#总价
price = item.find('span',class_="num").get_text()
#单价
price_pre = item.find('div',class_="price-pre").get_text()
#查看人数
num_look = item.find('div',class_='square').span.get_text()
print url,title,block,type,area,floor,orientation,buildtime,distance,tax,key,price,price_pre,num_look
datas.append([url,title,block,type,area,floor,orientation,buildtime,distance,tax,key,price,price_pre,num_look])
#子链接,标题,小区,户型,面积,楼层、朝向、建造时间,距离,满五,钥匙,总价,单价,查看人数
3)学会用lxml xpath解析网页
tree = lxml.html.fromstring(content)
html = lxml.html.tostring(tree,pretty_print=True)
#获取房子信息:下层链接,标题,小区,户型,面积,楼层、朝向、建造时间,距离,满五,钥匙,总价,单价,查看人数
#下层链接
urls = tree.xpath('//li/div[@class="info-panel"]/h2/a/@href')
print len(urls)
# for url in urls:
# print 'http://sh.lianjia.com'+url
#标题
titles = tree.xpath('//li/div[@class="info-panel"]/h2/a')
# for title in titles:
# print title.text
#小区
blocks = tree.xpath('//li/div[@class="info-panel"]/div[@class="col-1"]/div/a/span')
# for block in blocks:
# print block.text
#户型
types = tree.xpath('//li/div[@class="info-panel"]/div[@class="col-1"]/div/span[1]')
# for type in types:
# print type.text
#面积
areas = tree.xpath('//li/div[@class="info-panel"]/div[@class="col-1"]/div[@class="where"]/span[2]')
# for area in areas:
# print area.text
#难点,楼层、朝向、建造年代的内容居然再标签外
texts = tree.xpath('//li/div[@class="info-panel"]/div[@class="col-1"]/div[@class="other"]/div[@class="con"]')
# print texts
#楼层
floors = []
#朝向
orientations = []
#建造时间
buildtimes = []
for text in texts:
text = text.xpath('string(.)')
text = text.replace("n","").replace(" ","").replace("t","").split("|")
floors.append(text[1])
orientations.append(text[2])
if len(text)==4:
buildtimes.append(text[3])
else:
buildtimes.append(" ")
# for floor in floors:
# print floor
#
# for orientation in orientations:
# print orientation
#
# for buildtime in buildtimes:
# print buildtime
#距离
distances = tree.xpath('//span[@class="fang-subway-ex"]/span')
for distance in distances:
print distance.text
#满五
taxes = tree.xpath('//span[@class="taxfree-ex"]/span')
# for tax in taxes:
# print tax.text
#钥匙
keys = tree.xpath('//span[@class="haskey-ex"]/span')
# for key in keys:
# print key.text
#总价
prices = tree.xpath('//span[@class="num"]')
# for price in prices:
# print price.text
#单价
prices_pre = tree.xpath('//div[@class="price-pre"]')
# for price_pre in prices_pre:
# print price_pre.text
#查看人数
nums = tree.xpath('//div[@class="square"]/div/span[@class="num"]')
# for num in nums:
# print num.text
#获取房子信息:下层链接,标题,小区,户型,面积,楼层、朝向、建造时间,距离,满五,钥匙,总价,单价,查看人数
datas = []
i = 0
while i <len(urls):
url = "http://sh.lianjia.com"+urls[i]
title = titles[i].text
block = blocks[i].text
type = types[i].text
area = areas[i].text
floor = floors[i]
orientation = orientations[i]
buildtime = buildtimes[i]
distance = distances[i].text
tax = taxes[i].text
key = keys[i].text
price = prices[i].text
price_pre =prices_pre[i].text
num = nums[i].text
datas.append([url,title,block,type,area,floor,orientation,buildtime,distance,tax,key,price,price_pre,num])
i += 1
for data in datas:
print data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9],data[10],data[11],data[12],data[13]
4、数据的读写
函数:open('文件名‘,'参数’)
参数:w,wb,r,rb,a,ab
详细参考:Python文件I/O – Python教程 1)txt文件的读写
函数:write(‘数据’)
#存储到TXT
#建立文件
#设置文件名
title = "sh_lianjia_ershoufang"
#打开要写的文件,没有的话创建,参数w表示重新写入
file = open(title+".txt","w")
#开始写入文件
for data in datas:
# data = data.encode('utf-8')
file_data = []
for item in data:
item = item.strip().encode('utf-8')
#不能写入列表,只能一个一个写入,默认空格区分
file.write(item+",")
file.write("n")
# print file_data
# file.write(file_data)
print title+" is writed"
#txt的内容读取
file = open("sh_lianjia_ershoufang.txt","r")
f = file.readlines()
print f
for i in f:
print i
file.close()
2)CSV文件的读写
csvfile = file('csv_sh_lj_2s.csv','ab')
writer = csv.writer(csvfile)
for data in datas:
csv_data = []
for item in data:
item = item.strip().encode('utf-8')
csv_data.append(item)
writer.writerow(csv_data)
csvfile.close()
print "csv_sh_lj_2s.csv has been saved."
#csv的读取
csvfile_read = file('csv_sh_lj_2s.csv','rb')
reader = csv.reader(csvfile_read)
for line in reader:
print line
csvfile_read.close()
open(title,wb)的输出结果:
open(title.'w')的输出结果
3)MySQL的读写
#创建链接
params = dict(host='localhost',port = 3306 ,user ='root',password = 'root', database='test')
conn = connector.connect(**params)
#创建指标
cursor= conn.cursor()
#创建表:下层链接,标题,小区,户型,面积,楼层、朝向、建造时间,距离,满五,钥匙,总价,单价,查看人数
ddl = """
create table lianjia_sh(id integer, url varchar(100), title varchar(100), block varchar(100), type varchar(100), area varchar(100), floor varchar(100), orientation varchar(100), buildtime varchar(100), distance varchar(100), tax varchar(100), have_key varchar(100), price varchar(100), price_pre varchar(100), num varchar(100))
"""
#插入内容:
sqltext = """
insert into lianjia_sh(url,title,block,type,area,floor,orientation,buildtime,distance,tax,have_key,price,price_pre,num) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
# for data in datas:
# cursor.execute(sqltext,data)
# conn.commit()
# data_eg = ['/ershoufang/sh4281292.html','温馨之家,业主诚意出售,链家推荐,好房待售','梅陇二村','45.01平 ','中区/6层','朝南','1988年建','距离1号线莲花路站832米','满五','有钥匙','240','53321元/平','85']
cursor.executemany(sqltext,datas)
#指针提交,不然回滚
conn.commit()
conn.close
本文作为学习笔记,会不定期更新。
后续学习内容:
解决反爬虫机制
如何设立代理池
如果模拟登陆
本文很早就写好了,但是居然一直忘记发布,原来一直在草稿箱里。。。。。算了 就给自己当笔记用吧
下一篇: 外贸推广:谷歌SEO核心要点




 售前咨询
售前咨询



您好!请登录