 深圳南山seo
深圳南山seo
智能采集上传银行系统的竞争力在哪里?SEO排名软件
浏览次数:56 分类:SEO优化
官方数据:温州文章智能采集上传银行系统的竞争力在哪里?
核心方法:网站SEO关键词优化软件使用方法
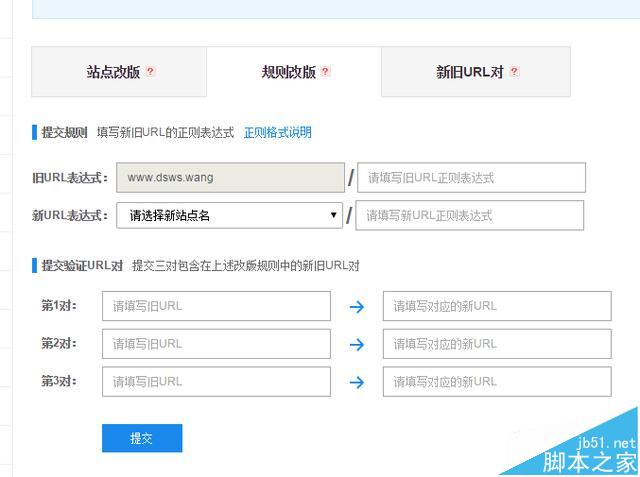
SEO排名软件,什么是SEO排名软件。SEO排名软件是一款辅助SEO排名的软件。为什么很多人说SEO排名软件没用?SEO排名软件只是基础,也可以说是辅助功能。更重要的是,要做好SEO网站的优化工作。今天给大家分享一款免费的SEO排名优化软件,它还支持针对不同网站的站内优化功能。详见图片教程。
SEO优化需要学习的内容其实比较常见。例如,SEO排名软件需要学习建站、文案编辑、平面设计等知识。当然,你还需要有一定的分析思路的能力,这些都是不同专业的科目。但是玉泉区网站seo优化排名,在搜索引擎优化技术的研究中,应该进行系统的研究。
为什么要研究这么多交叉学科?这就是搜索引擎优化技术的核心魅力。有些朋友已经决定放弃网站的搜索引擎优化,因为搜索引擎优化不专业,网站没有得到很好的关键词排名结果。一直认为搜索引擎优化没用,其实不是没用,是自己操作不当造成的。
想要优化网站,首先要有扎实的学习基础。seo排名软件学习到的所有内容都应该在技术上得到控制,这样才能针对不同属性的网站给出更合理的优化方案。优化方案的制定也能充分体现出对SEO优化思想缺乏扎实的学习和理解。
” />
seo优化学习的核心内容是让网站页面更有利于用户体验,通过策划相应的需求关键词来解决用户需求。在此基础上,seo排名软件通过一系列的技术操作来满足搜索引擎的排名规则,使网站页面质量有利于关键词排名的提升,从而达到预期的效果。
围绕用户体验的一系列学习内容需要SEO高手掌握。当然最后的seo优化一定要结合seo边缘知识点,才能达到更多的优化效果。因此,SEO优化学习是一个不断更新和扩展的渐进过程,需要具备较高的学习能力,才能真正在SEO优化领域取得好的成绩。

有很多网页制作者都是先开始建网站,然后一周左右就开始优化网站。他们在两周内想不出一个确定的排名问题,但结果却令人震惊。刚上线的时候还在第二页。想努力上首页,却出现了奇怪的现象。我发现最近半个月的排名有时会出现在第二页,有时会消失。其实出现这种情况是因为网页搜索引擎优化没有做好,对网页进行升级,通过数据分析,提高了网页的点击率。
目前,百度推出了“优采云
算法”。SEO排名软件旨在严厉打击销售软文和目录的新闻来源。触发“优采云
算法”问题的站点将被清算为新闻来源,同时降低其声誉。在百度搜索系统中的评价,如果不了解搜索规则,会导致搜索引擎的应用度不高,导致网页在搜索引擎中的排名偏低。SEO学院通过精准分析,帮助网页制作者找到自己的定位和未来的发展目标,无需涉及百度的“优采云
算法”。
” />
seo优化提交的技术操作一般分为自动提交、手动提交和站点地图提交等几种方式。这些表的选择可以根据网站的属性来区分。当然,这也要看站长优化人员的习惯。

Submission自身的技术操作是为了让搜索引擎能够在更短的时间内收录网站页面的URL链接,从而捕捉并记录新增的页面内容。例如,自动推送方式是最快的提交方式,seo排名软件可以直接快速地将网站页面的实时更新内容提交给搜索引擎,从而有效地增加网站页面的收录量。
对于很多大型网站来说,每天都有大量的内容和更新。在此基础上,必须以站点地图的形式批量提交站点地图,这样搜索引擎才会养成定时抓取站点地图的习惯,但这种提交方式要满足自动推送提交方式。
如果想通过自己的控件提交url链接,需要手动提交。这种方式通常是一种提交方式,只有在网站未收录的新增内容和页面进行二次优化后才会采用。这种方法一般适合搜索引擎优化专家级别的搜索引擎优化人员操作,因为对于没有被收录的页面,在优化操作完成后使用这种方法是比较正确的。
提交URL链接的核心作用是缩短关键词的排名周期。seo排名软件使搜索引擎蜘蛛能够在最短的时间内抓取网站的新内容,达到快速收录的效果。这样做的好处是它保持了一些网站更新的原创
内容。即使其他网站曾经收录过该内容玉泉区网站seo优化排名,只要其网站内容是第一次收录,就可以避免被搜索引擎判断为转载其他网站的内容,从而有效提高网站在收录方面的优势。有竞争力的设计关键字。
操作方法:快速掌握Python数据
” target=”_blank”>采集与网络爬虫技术(附代码及操作案例)
大家好,我是曹鑫老师。今天要和大家分享的是在线数据的自动批量采集和整理。大家比较熟悉的名字是“爬虫”。
扫码预约九宫格资料
线下体验店
在课程开始之前,我想说一个免责声明:本课程只讨论数据抓取的相关知识,不要利用抓取的数据做损害访问网站商业利益的事情。例如,您还创建了具有相同业务的网站;不对访问网站的服务器造成压力,影响正常用户访问。以上就是大家以后采集
资料时需要注意的地方。那么我们继续聊技术,数据采集对我们的日常工作有什么帮助?让我给你举个例子。
比如我们来到CDA官网的直播公开课页面,可以看到这里有很多课程,每门课程的组成部分都是一样的,包括主题海报、标题内容、老师介绍和头像,同时,我可以翻页到下一页,看看更多往期公开课。相信大家在很多网站上都看到过这种结构。你必须认为你今天学到的东西几乎可以应用。去类似的网站。
接下来,如果你想把这些内容都整理成一个Excel表格,应该怎么办呢?第一反应是不是:那就去把题目一个一个复制,老师名字复制一个,介绍内容复制一个一个粘贴到Excel表格里?没错,这就是我们要做的,但是用鼠标一个一个点击,在键盘上敲`Ctrl+C`,`Ctrl+V`,太累了。这是日常工作中的典型场景:任务操作一点都不难,但是需要反复操作,费时费力。
如果我掌握了 Python 数据采集
,我将如何解决这个重复性的任务?先给大家看看效果吧。代码不难,就这么一段,你现在肯定一头雾水,别着急,小编带你一段一段的看懂。

点击`Shift+Enter`,我们运行代码看看:
1、浏览器自动打开指定页面,即直播公开课的第一页。
2、在Anaconda中,星号表示代码区正在运行,打印结果会输出到代码区下方。
3.循环获取数据后,代码立即获取第一页的内容,整理成表格打印出来。
4. 然后,浏览器自动翻页到第二页,再次获取第二页的内容,整理成表格打印出来。
5.继续,第三页,同样的输出。
6. 最后输出一个Excel文件。让我们打开看看。所有页面我需要的数据都整理好了。
达到了我们想要的效果,有几个好处:
1.我只是点击鼠标移动到代码区;我在键盘上按了`Shift+Enter`启动了程序,然后就不用再点鼠标,不用敲键盘了,都交给Python程序了
2.我现在是3页,我想得到10页,100页,1000页,我只需要在这里改变数字,让它循环10次,100次甚至1000次,不需要花费更多的时间和体力总是一个接一个跑,剩下的体力活全部交给Python。
一旦掌握了数据采集
技术,就可以将类似的重复性工作自动化。
下面是分享给大家的代码,大家可以自己试试。
# 调用包
from selenium import webdriver
from lxml import etree
import pandas as pd
# 启动浏览器打开指定网页
browser = webdriver.Chrome(‘/Users/davidfnck/Downloads/chromedriver’)
 售前咨询
售前咨询



您好!请登录